

그림 윤슬 ·소프트 그라데이션 에어브러시
번역기로 보면 안 보이는 것
사람들은 대형 언어 모델을 거대한 번역기쯤으로 여긴다. 한국어로 물으면 한국어로 답하니, 모델 안에 한국어 방이 따로 있고 영어 방이 따로 있으리라 상상한다. 틀렸다. 모델 안에 방 같은 건 없다. 단어와 문장은 수십억 개의 숫자, 즉 가중치라는 한 덩어리의 좌표 공간 위에 흩어져 박혀 있다. 어떤 언어가 그 공간에서 넓은 자리를 차지하느냐는 학습 데이터에 그 언어가 얼마나 많이, 얼마나 다양하게 들어갔느냐로 갈린다.
여기서 첫 오해가 시작된다. 한국어로 매끄럽게 답한다고 해서 모델이 한국어를 영어만큼 깊이 아는 건 아니다. GPT 계열이든 Gemini든 Llama든, 공개된 학습 코퍼스 분석을 보면 영어가 압도적이고 한국어는 대개 1퍼센트 안팎의 작은 조각에 그친다. 모델은 부족한 한국어 지식을 영어에서 배운 세계관으로 메운다. 그래서 한국 법제도나 부산의 지역 현안을 물으면, 문장은 유창한데 내용은 미국 뉴스룸의 상식을 한국어로 갈아입힌 답이 나오곤 한다.
토큰이라는 단위, 영토라는 비유
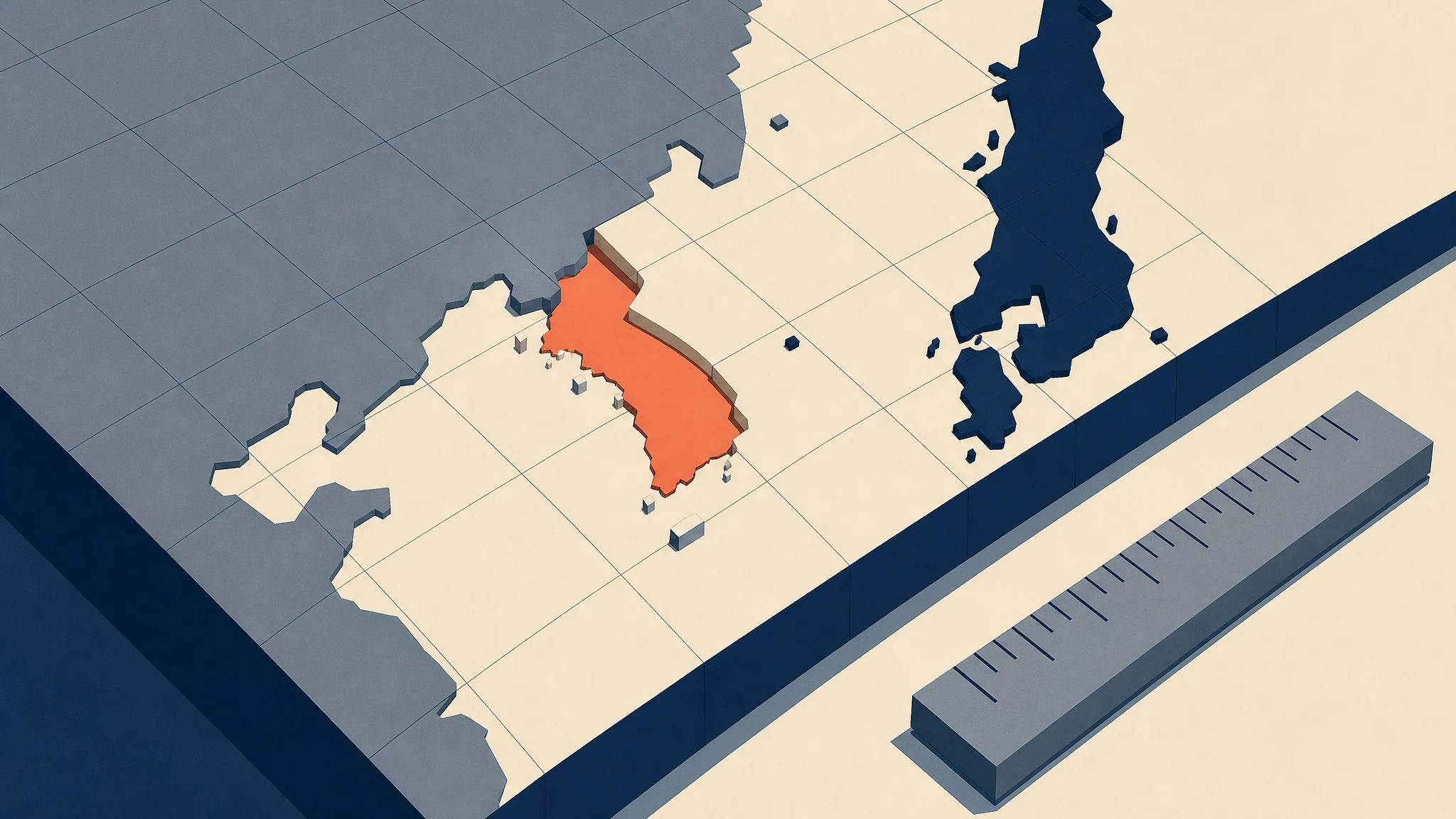
언어를 '표현 수단'으로만 보면 이 격차가 사소해 보인다. 번역은 되니까. 그러나 모델 내부에서 언어는 표현이 아니라 자리다. 가중치 공간을 한 장의 지도라고 해보자. 영어는 대륙이고, 한국어는 그 대륙 가장자리에 붙은 좁은 해안선이다. 해안선이 좁다는 건 단어가 부족하다는 뜻이 아니다. 한국어로 표현된 맥락, 뉘앙스, 판례, 속담, 행정 용어, 지역 정서가 모델의 추론에 끼어들 통로가 좁다는 뜻이다.
토큰은 그 영토의 측량 단위다. 한국어는 교착어라 같은 의미를 담아도 영어보다 토큰을 더 많이 쓴다. 같은 질문에 비용이 더 들고, 같은 맥락 창에 더 적게 들어간다. 영토는 좁은데 입장료는 비싼 셈이다. 불편의 문제가 아니라 구조의 문제다. 한국어 사용자는 더 비싸게, 더 얕은 추론을, 더 적은 맥락으로 받는다. 이 비대칭을 단 한 번이라도 수치로 들여다본 한국 부처가 있는가.
그러니 개인 사용법은 핵심이 아니다
여기서 흔한 반론이 나온다. "한국 기업이 자체 한국어 모델을 만들고 있지 않은가. 시장이 알아서 푼다." 반은 맞다. 네이버의 하이퍼클로바, LG의 엑사원, 카카오의 시도들은 진짜 영토 확장이다. 그러나 시장은 영토를 넓힐 뿐, 영토를 측정하고 지키는 일까지 하지는 않는다. 기업은 자사 모델의 한국어 성능을 자랑할 동기는 있어도, 글로벌 모델 안에서 한국어가 해마다 작아지는지 커지는지를 공개적으로 추적할 동기는 없다. 그건 국가가 할 일이다.
문제를 개인의 프롬프트 실력으로 좁히는 순간 본질이 사라진다. "AI를 잘 쓰는 법"을 가르치는 강의는 넘친다. 정작 우리가 묻지 않는 질문은 이것이다. 우리 다음 세대가 일상적으로 사고를 위탁하게 될 모델 안에서, 한국어로 쌓인 지식과 정서는 얼마만큼의 자리를 가지고 있는가. 그 자리는 누가 측정하는가.
한국이 아직 정의하지 못한 빈칸
여기 제도의 빈칸이 있다. 한국은 공공 언어 데이터를 가졌다. 국립국어원의 말뭉치, 법제처의 법령 데이터, 방대한 행정 문서와 판례. 그런데 이것들이 어떤 조건으로 글로벌 모델 학습에 들어가는지, 들어가도 되는지, 들어간 대가로 무엇을 받는지에 대한 국가 기준이 없다. 저작권법 개정 논의는 창작자 보호에 머물러 있고, 공공 데이터를 '모델 가중치 속 한국어 영토'를 넓히는 전략 자산으로 다루는 관점은 행정 어디에도 자리 잡지 못했다.
책임성의 빈칸도 마찬가지다. 글로벌 모델이 한국 청소년에게 한국 현대사를 잘못 답하거나, 부산의 재난 대응 정보를 미국식으로 답할 때, 그 오류는 누구의 책임인가. 영어 데이터로 메워진 빈자리에서 나온 환각을 '문화적 손실'로 측정하는 지표가 우리에겐 없다. 측정하지 않는 것은 관리되지 않고, 관리되지 않는 것은 조용히 줄어든다. 한국어의 자리는 그렇게, 아무도 결정한 적 없는 채로 해마다 작아질 수 있다.
이건 정서적 호소가 아니라 측정 가능한 제안이다. 주요 글로벌 모델의 한국어 토큰 비중, 한국어 추론 정확도, 한국어 입장 비용을 해마다 공표하는 공공 관측소 하나면 시작할 수 있다. 환율을 매일 고시하듯, 우리 언어가 기계의 머릿속에서 차지하는 환율을 고시하는 일이다.
잘 쓰는 나라보다, 제대로 이해하는 나라
AI를 잘 쓰는 나라는 많아질 것이다. 누구나 같은 모델에 접속하니까. 진짜 차이는 그다음에서 갈린다. 이 기술이 우리 언어와 지식을 어떤 비율로 담고 있는지 측정하고, 그 비율을 국가 전략으로 끌어올릴 줄 아는 나라와 그렇지 못한 나라. 전자는 모델 안의 한국어 영토를 지키고, 후자는 유창한 답변에 안심하다가 영토가 줄어든 줄도 모른다.
우리는 이 기술을 사회적으로 이해하고 있는가. 아직 아니다. 한국어가 가중치 속에서 작아지는 일은 번역의 문제가 아니라 주권의 문제다. AI를 잘 쓰는 나라가 되기 전에, 우리 언어가 기계 안에서 어디에 서 있는지부터 제대로 이해하는 나라가 되어야 한다.
이 글이 좋았다면 눌러주세요
글쓴이

이 글이 유용했다면 공유해 주세요
받아쓰기 칼럼 더 보기 →





